近日,Apache InLong成功從孵化器畢業,正式成為Apache軟件基金會的頂級項目,標志著其在數據流處理領域的成熟與認可。該項目專注于構建高效、可靠的數據處理與存儲服務,其核心亮點在于能夠支持百萬億級別的數據流處理能力。
一、Apache InLong概述
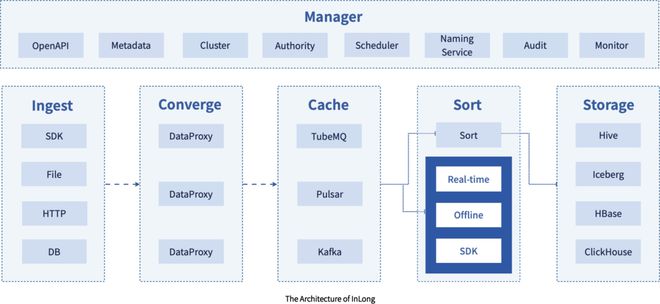
Apache InLong(原名TubeMQ)是一個一站式的數據流接入與處理平臺,旨在簡化數據采集、聚合、存儲和分發的全流程。其設計目標是為大規模數據場景提供低延遲、高吞吐的解決方案,尤其適用于實時數據流處理需求。
二、技術亮點與核心能力
- 百萬億級數據流處理能力:Apache InLong通過分布式架構和優化的消息隊列機制,實現了對海量數據的高效處理。它能夠輕松應對每日百萬億條數據流的接入與傳輸,確保數據在復雜網絡環境下的穩定流動。這種能力得益于其可擴展的節點設計和負載均衡策略,使得系統在數據量激增時仍能保持高性能。
- 數據處理與存儲服務集成:InLong提供一體化的數據處理框架,支持多種數據源(如日志、數據庫、IoT設備)的實時采集,并通過內置的ETL(提取、轉換、加載)功能進行數據清洗和轉換。同時,它與主流存儲系統(如HDFS、Kafka、ClickHouse)無縫集成,實現數據的快速存儲和查詢,降低了用戶在多系統間切換的復雜性。
- 高可靠性與容錯機制:項目采用多副本和數據校驗技術,確保數據在傳輸和存儲過程中的完整性與一致性。即使出現節點故障,系統也能自動恢復,避免數據丟失,這對企業級應用至關重要。
- 易用性與生態系統兼容:InLong提供友好的管理界面和API,支持快速部署和監控。它與Apache生態系統中的其他項目(如Flink、Spark)深度整合,助力用戶構建端到端的數據管道。
三、應用場景與未來展望
Apache InLong的畢業不僅是對其技術實力的肯定,也為大數據行業帶來了新的選擇。它廣泛應用于金融風控、物聯網數據分析、日志監控等場景,幫助企業在海量數據中挖掘價值。未來,隨著AI和實時計算需求的增長,InLong有望通過持續優化,進一步降低數據處理門檻,推動數據驅動決策的普及。
Apache InLong作為頂級項目,憑借其百萬億級處理能力和一體化服務,正在成為數據流處理領域的重要基石。用戶可通過官方文檔和社區資源,快速上手并受益于其強大功能。