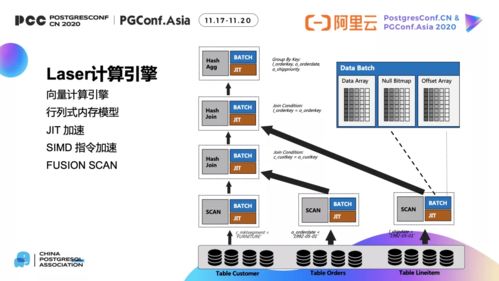
隨著企業數據量的爆炸式增長和數據應用場景的日益復雜,傳統的MPP(大規模并行處理)架構數據倉庫正經歷一場深刻的云原生變革。從最初的托管服務模式,到如今全面擁抱云原生技術棧,這一演進不僅提升了數據處理與存儲的效率、彈性與成本效益,更重塑了數據服務的構建與交付方式。
1. 托管服務的興起與局限
在云計算早期,許多企業選擇將MPP數據倉庫(如Teradata、Greenplum的托管版本)部署在云基礎設施上,即“托管服務”模式。這種模式減輕了硬件采購、運維和擴展的負擔,用戶能夠更專注于SQL開發與業務分析。托管服務通常基于預置的虛擬機或物理機集群,其資源分配相對固定,擴容縮容周期較長,且難以實現細粒度的資源隔離與成本優化。數據處理與存儲服務仍在一定程度上受限于底層基礎設施的剛性。
2. 云原生的核心驅動力
云原生理念的普及,特別是容器化、微服務、聲明式API和彈性編排等技術的成熟,為MPP數據倉庫的現代化改造提供了全新路徑。其核心驅動力在于:
- 彈性與敏捷性:通過Kubernetes等編排平臺,計算與存儲資源可以實現秒級伸縮,輕松應對突發的查詢負載或數據吞吐需求。
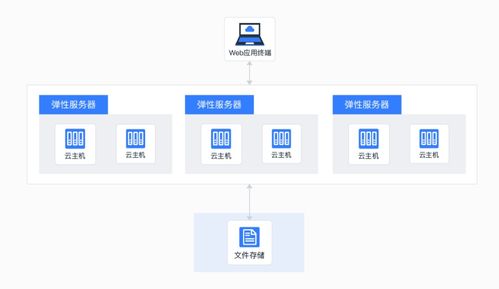
- 成本精細化:存算分離架構成為可能,計算節點可按需啟停,存儲則利用對象存儲(如S3、OSS)實現低成本、高持久性的數據湖化存儲。
- 服務化與自動化:數據處理流水線、元數據管理、備份恢復等能力可通過Operator或自定義控制器實現自動化運維,提升平臺整體SLA。
- 生態集成:云原生數據倉庫更容易與上下游服務(如流處理、AI/ML平臺)無縫集成,構建統一的數據云原生棧。
3. 數據處理服務的云原生實踐
在云原生架構下,MPP數據倉庫的數據處理服務呈現出以下特征:
- 計算容器化:將查詢引擎、事務協調器等核心組件封裝為容器,利用Kubernetes進行調度與生命周期管理,實現資源隔離與高可用部署。
- 彈性執行引擎:基于實時負載動態調整執行器(Executor)實例數量,甚至支持查詢級資源隔離與優先級調度,避免資源爭搶。
- 數據本地性優化:通過緩存層(如Alluxio)或智能數據放置策略,在存算分離背景下盡可能減少網絡開銷,保持MPP架構的高性能優勢。
- Serverless交互:對外提供Serverless SQL端點,用戶無需關心集群規模,按實際掃描/處理數據量付費,極大降低使用門檻與成本。
4. 存儲服務的云原生重構
存儲層是云原生轉型的關鍵一環:
- 對象存儲作為主存:將數據持久化在兼容S3協議的對象存儲中,獲得近乎無限的擴展能力、極高的數據耐久性以及顯著低于傳統SAN/NAS的成本。
- 分層存儲與智能緩存:根據數據熱度自動分層,熱數據緩存在本地SSD或高性能分布式緩存中,冷數據下沉至對象存儲,平衡性能與成本。
- 元數據與數據解耦:元數據(如表定義、分區信息、統計信息)獨立管理,可能存儲在分布式鍵值庫(如etcd)或專用元數據服務中,確保其高可用與強一致性。
- 統一數據湖倉格式:采用開放數據格式(如Apache Iceberg、Delta Lake、Hudi),使得數據倉庫可以直接高效地查詢數據湖中的數據,實現湖倉一體的融合架構。
5. 挑戰與未來展望
盡管云原生帶來了巨大優勢,實踐過程中也面臨挑戰:存算分離架構下的網絡延遲對復雜查詢性能的影響、跨區域數據訪問的成本與合規性、多云/混合云環境下的一致管理體驗等。MPP數據倉庫的云原生實踐將更深度地融合AI for Data(智能調優、自動索引)、無縫的數據共享與安全治理,并向更加自治、自適應、多模態的智能數據平臺演進。
從托管到原生,不僅是部署模式的變遷,更是數據處理與存儲服務理念的重塑。通過擁抱云原生,MPP數據倉庫正進化成為彈性、高效、經濟且易于集成的現代化數據核心,持續賦能企業數據驅動決策與創新。